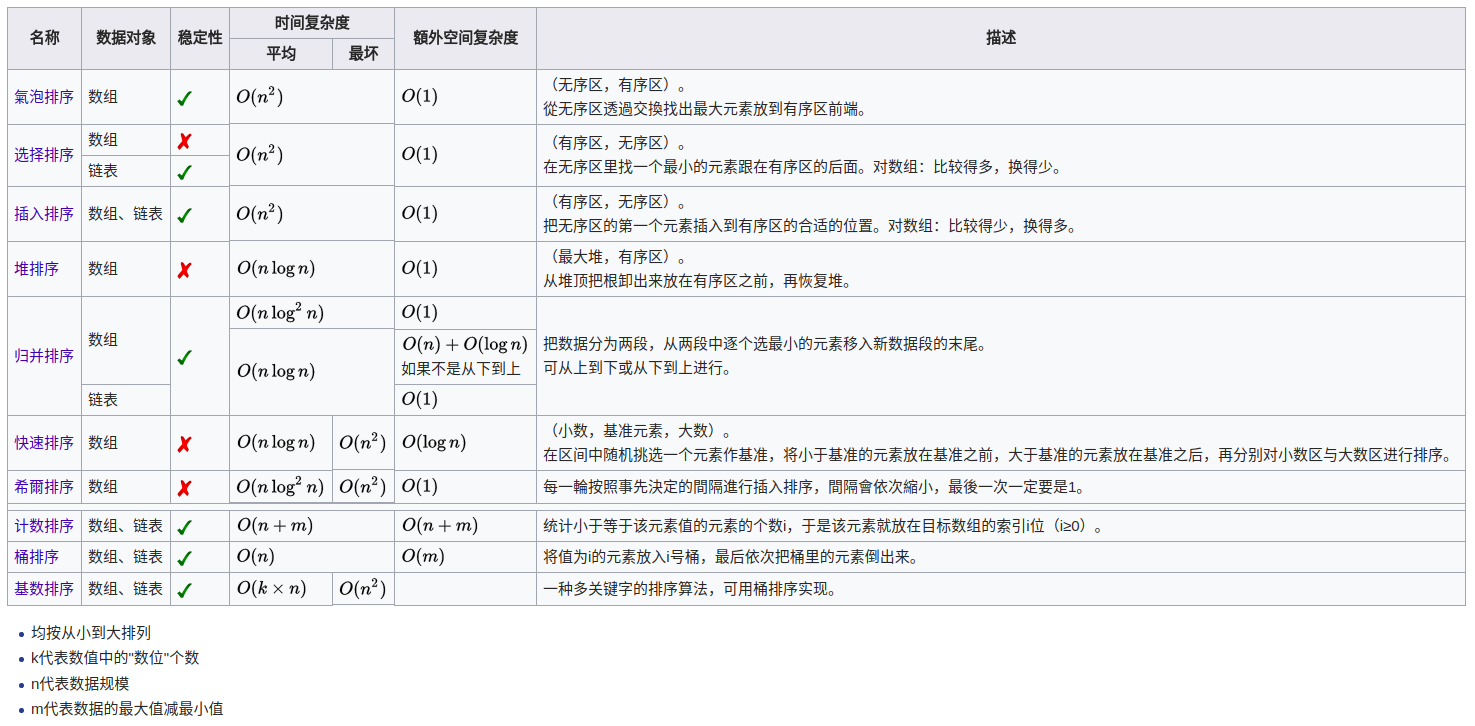
上面这幅图是从维基百科上截取的,我们可以看到,常见的排序算法有:冒泡排序、选择排序、插入排序、堆排序、归并排序、快速排序、希尔排序、计数排序、桶排序以及基数排序;在图中都已经体现了每个排序算法的时间复杂度和空间复杂度以及排序算法的稳定性(排序算法的稳定性是指如果存在两个或以上的相同元素,在排序过程中,如果ri=rj,且i<j,在排序过程中这种关系保持不变的则称该排序算法具有稳定性)。
今天,我们来讲讲插入排序以及希尔排序。
插入排序
插入排序,假设有N个数,那么通过N-1趟循环对元素进行位置的正确 插入排序,而插入排序依靠这样一个事实,在第m次排序时(就是到了第m个元素的时候),前m-1个元素都是有序的事实,下面,我们来通过一张表来看看插入排序是如何实现的(假设数组名为A)

当m=1时,我们从数组下标为1的元素作为第m个元素,那么,由插入排序依靠的事实——前m-1个元素有序,因此,我们对A[m]和A[0..m-1]进行比较找到A[m]适合的位置进行插入,然后我们不断改变第m个元素的位置,不断的对m-1个元素进行寻找适合他们自己插入的位置,当m为数组长度时,已经完成了对整个数组元素的排序,此时就可以跳出循环。
插入排序代码
1 | void Insert(ElementType A[], int N) { |
这个算法就是插入算法,是不是很简单?现在,我们来分析下插入排序的时间复杂度是如何算的,我们观察算法,算法的主体实际是两个for循环,当m=1时,内层循环做了一次;当m=2时,内层循环做了两次……因此,我们可以算出时间复杂度为:1+2+3+4+…+N=O(N^2)
希尔排序
希尔排序可以看作是优化过的插入排序,只不过从原来的相邻开始进行插入排序,变成了相隔n个元素进行插入排序,而算法的结束就是当相隔的距离减小到只比较相邻两个元素为止;在使用增量序列进行排序时,每一趟的排序结果,对于每一个i,都有A[i]<A[i+mk],所有相隔mk的元素都被排序,因此叫做mk-排序;在这里,希尔排序有一个很重要的性质:一个mk-排序后的序列,保持他的mk-排序性。这里有一个排序分步表让我们来理解下希尔排序:

对于希尔排序中间隔大小组成的序列m0、m1、m2、…m(k-1),我们称这个序列为增量序列,只要m0=1的增量序列都是可行的,但是对于算法的影响,不同的增量序列影响不同,可能增量序列h1比增量序列h2更好,因此便存在一个最有的增量序列。对于增量序列,目前流行的使用是Shell建议的序列(但是这个增量序列不是最优的):mt=N/2(向上取整)和mk=m(k+1)/ 2(向上取整)。然后我放上希尔排序的算法,其实和上面的插入排序的算法只是多了一点对于增量的选取计算循环而已:
希尔排序代码
1 | void ShellSort(ElementType A[], int N) { |