

邻接多重表
什么是邻接多重表?图的数据结构表示有很多,邻接矩阵、邻接表、还有今天要将的邻接多重表和十字链表,都是很经典的图的数据结构表示。一般来说,在邻接表上容易找到任一顶点的第一个邻接点和下一个邻接点,但是如果邻接表存储的是无向图类型的话,对于边的操作很麻烦,需要对两条链表进行判断操作,而邻接多重表就是为了解决邻接表存储无向图带来的操作麻烦而诞生的,这里引用下c语言中文网的段落
Read More...什么是邻接多重表?图的数据结构表示有很多,邻接矩阵、邻接表、还有今天要将的邻接多重表和十字链表,都是很经典的图的数据结构表示。一般来说,在邻接表上容易找到任一顶点的第一个邻接点和下一个邻接点,但是如果邻接表存储的是无向图类型的话,对于边的操作很麻烦,需要对两条链表进行判断操作,而邻接多重表就是为了解决邻接表存储无向图带来的操作麻烦而诞生的,这里引用下c语言中文网的段落
Read More...
Swagger是什么?官方的定义是:A POWERFUL INTERFACE TO YOUR API。简单来说,Swagger就是将后台提供的restful-api进行在前端展示并提供测试所用。
api文档的书写,就我个人而言,是极其难受的一件事情,首先你要将你所提供API的功能作用和使用方法向前端人员说明,不善言语的我是真的难以言表,Swagger正好解决了我的痛苦,我只需要通过在对应restful-api的方法上提供注解,Swagger就会通过一系列反射来动态生成一个.json文件,这个.json文件的信息就是restful-api的信息,然后通过前端js的解析展现json数据,转换成前端html页面所展示的数据。具体如下图所示:
Read More...查找在数据结构中十分常见,查找某个元素是否在某个集合之中,并且通常伴随着插入与删除操作,而查询之后是否还有其他动作,将查询分为静态查询和动态查询;
而查找的对象——由具有同一类型(属性)的数据元素(记录)组成的集合,则对应着静态查找表和动态查找表;今天,我们讲讲两个静态查找表的方法——斐波那契查找与分块查找。
前一章我们讲了图的最小生成树的算法,今天我们来讲一讲最短路径的算法——Dijkstra算法与Floyed算法。
Dijkstra算法,目的是求的图中的一点,到其余顶点的最短路径;Floyed算法,目的是求图中任意两个顶点之间的最短路径。其实从Dijkstra算法去实现Floyed算法很简单,再多做一次循环去计算每个顶点到除了它自己的其他点的最短路径即可,之所以会有Floyed算法,是由于Floyed算法的简洁优美(Floyed算法的思想是利用了动态规划的思想)。现在,我们具体来介绍下这两个算法吧!
Read More...今天,我们来介绍最小代价生成树这一算法。最小生成树的算法有三个,一个是prime算法,一个是kruskal算法,另一个是Boruvka算法。这三个算法都是解决最小代价生成树这一问题的,在这里我们只说prime算法和kruskal算法,那么这两个算法有什么不同呢?图我们知道,有稠密图和稀疏图(引入下定义:数据结构中对于稀疏图的定义为:有很少条边或弧(边的条数|E|远小于|V|²)的图称为稀疏图(sparse graph),反之边的条数|E|接近|V|²,称为稠密图(dense graph)。)。由于这两个算法的贪心策略不同,在面对稠密图时,prime的算法的时间复杂度为O(V^2)[v为顶点的个数],kruskal算法的时间复杂度为O(E * logE)[E为边的条数],而稠密图的E是大于V的,所以kruskal算法时间复杂度反而大于prime算法;在面对稀疏图时kruskal算法是优于prime算法的。
Read More...什么是图,简单的来说,图就是由顶点集V和边集E构成,假设我们的顶点集有n个顶点,那么我们的边可以是从0到(n(n-1))/2这么多,如果还考虑方向的话,那么边的条数将达到nn,所以,我们根据边的特性,将图分为了有向图,有向网,无向图,无向网;我们根据边是否有向分类,同时,我们在根据边的信息的特征再细分下去,图的边是没有权值的,网的边的是带有权值的。下面两幅图,左边的有向网,右边的是有向图,从边是否带有权值就可以区分。
[gallery ids=”428,427” type=”rectangular” link=”file”]
Read More...哈夫曼树,又称带权路径长度最短的二叉树。那么什么是带权路径长度最短的二叉树呢?这里我引用维基百科的解释:哈夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树。所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数)。树的路径长度是从树根到每一结点的路径长度之和,记为WPL=(W1L1+W2L2+W3L3+…+WnLn),N个权值Wi(i=1,2,…n)构成一棵有N个叶结点的二叉树,相应的叶结点的路径长度为Li(i=1,2,…n)。可以证明霍夫曼树的WPL是最小的。光看文字可能看不明白,接下来我们就用图来说明下。
Read More...我们知道,一棵二叉树,每个节点有两个指针域,分别指向该节点的左子树与右子树。现在,我们有一棵二叉树,我们假设这棵二叉树拥有n个节点,那么,空指针域有多少个呢?n个节点之间由n-1个指针连接起来,而n个节点,总共有2*n个指针域,所以,我们很容易算出,一棵拥有n个节点的二叉树,空指针的个数为n+1个。
在前一篇文章中,我们介绍了二叉查询书树的一些基本操作,其中,我们来看下遍历操作1
2
3
4
5
6
7
8//中序遍历
void PrintTreeMid(Tree tree) {
if (tree) {
PrintTreeMid(tree -> LeftTree);
cout << tree -> data << " ";
PrintTreeMid(tree -> RightTRee);
}
}
今天我们讲讲树这个结构。与之前的链表,栈,队列不同,之前的这些数据结构都是线性的,而今天的树,则是一种非线性结构。树这种结构,最常见的就是菜单以及win/mac/linux下的目录系统。
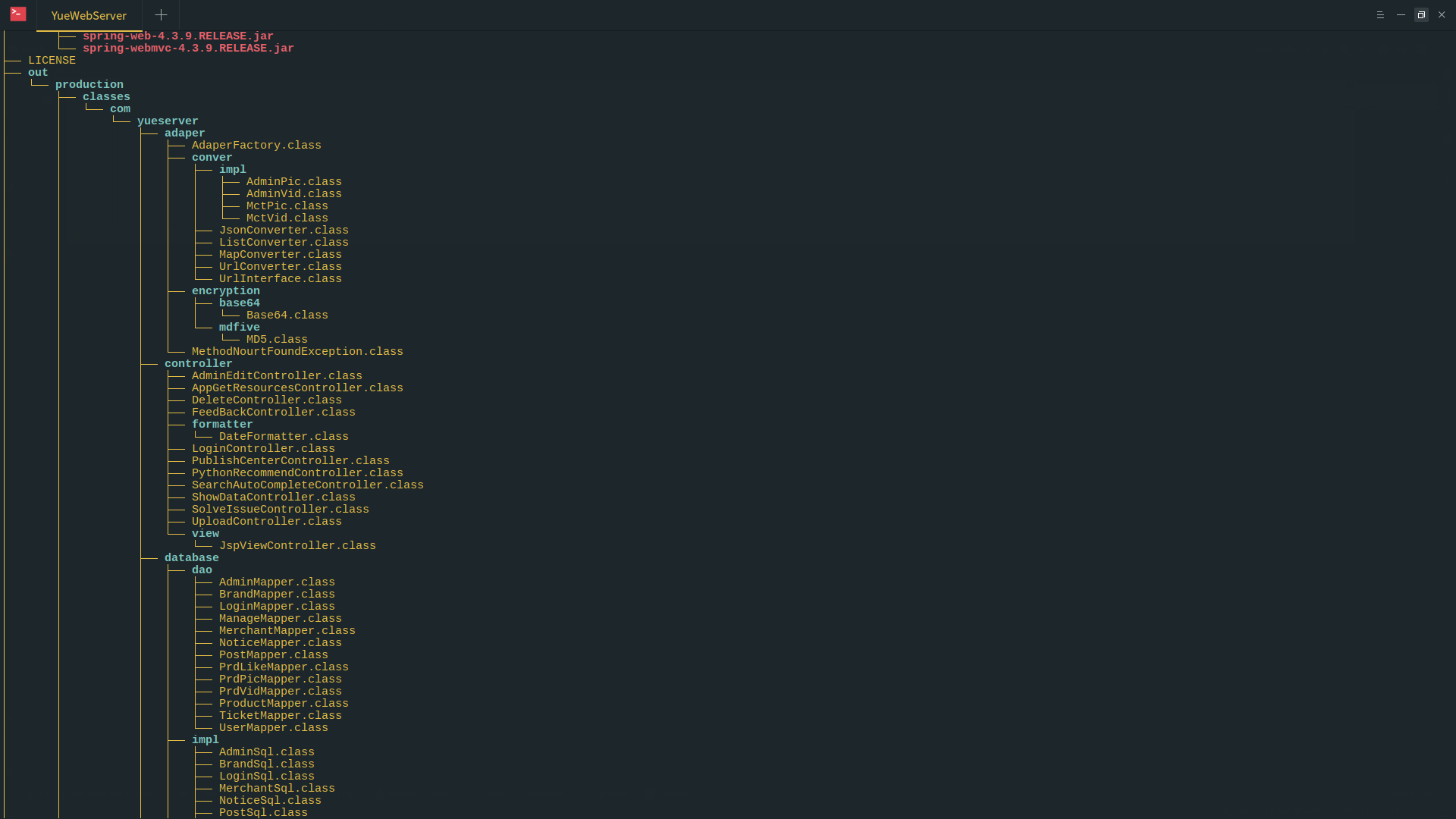
通过这张图我们可以很形象的了解目录结构的树型结构,我们以out文件夹为例:out文件夹是一个父文件夹,我们也可以看做是一个根节点,而production是out的一个子文件夹,我们可以称之为子节点,同时,我们又看到,production下还有classes文件夹,我们称classes文件夹为production的子文件夹(子节点),production为classes的父文件夹(父节点),因此,父节点与子节点是相对的,但是,根节点只有一个,就是out文件夹。现在,我们来看AdaperFactory.class这个文件,注意,这是一个文件了,相当于叶子了,他没有再包含文件夹,处于末端,因此这种情况就是树结构中的树叶,没有任何子节点的一个结点。
Read More...所需的js与css文件:1
2
3
4
5
6
7
8
9
10
11
12
13bootstrap.min.css
datepicker3.css
bootstrap-editable.css
bootstrap-table.min.css
bootstrap-dialog.css
jquery-1.11.1.min.js
bootstrap.min.js
bootstrap-editable.js
bootstrap-table.js
bootstrap-table-editable.js
bootstrap-dialog.js
jquery-form.js
弹出窗口的html代码:
Read More...